librosa parameter 분석 : mfcc_to_mel_2
이번엔 parameter 에 대해 비교 분석해보겠다.
우선 n_mels 비교.
공식문서에서는 mel frequency 의 수라고 되어있는데, default 는 128 이다.
우선 시각화를 해보겠다.

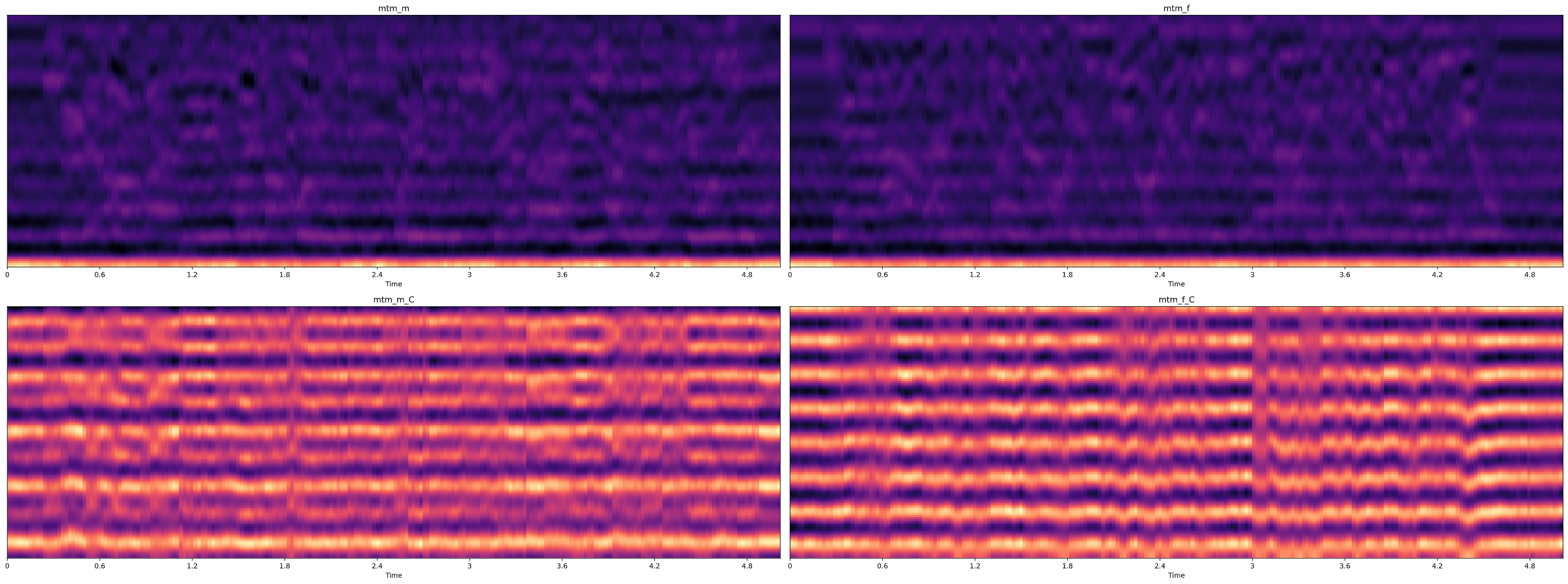
처음 n_mels 를 반수인 64로 해봤을 땐 큰 차이를 느끼지 못 했지만, 그보다 훨씬 적은 숫자를 입력하니 위와 같이 유의미한 차이를 얻을 수 있었다.
즉, n_mels 는 공식문서에 나와있는대로 y 축에 대한 행의 수를 지정해주는 것이라 보면 되겠다.
이 때 y 축은 말했던대로 frequency 가 된다.
그러나 default 값보다 더 높게 주는 경우에는 보다시피 큰 차이를 느끼기 어려웠다.
다음은 DCT 에 관한 내용이다.
mfcc 데이터를 만들 때 DCT 란 것을 사용한 뒤 feature selection 을 통해 데이터들을 추려내는 과정을 겪는데, mfcc_to_mel 의 경우에는 이를 역산하기 때문에 다시 한 번 DCT 가 등장하게 된다.
이 때 사용하는 DCT 를 조절하는 변수이다.

그러나 default 값인 2 와 다른 값인 1, 3 을 주어도 해당 데이터로는 그래프 상에서는 큰 변화가 일어나지 않았다.
DCT : 이산 코사인 변환
mel filter bank 를 거친 데이터를 log scale 시키고 최종적으로 DCT 를 거치게 되는데, 이 때 DCT 란 낮은 계수의 차원 데이터 (정보량이 많음) 12개들만 남기는 것을 뜻한다.
이렇게 DCT 를 거친 12개의 feature 와 그 것들을 전부 합친 energy 들을 가르켜 mfcc 라고 부른다.
(출처 : hyunlee103.tistory.com/48)
ref 변수는 mfcc 에서 mel spectrogram 으로 되돌릴 때 필요한 dB 계산을 위한 기준이라고 하는데 default 인 1.0 과 0.001, 1000.0 으로 비교해봐도 음성 데이터에서는 큰 차이를 느끼기 어려웠다.

음성 데이터는 각 dB 간의 큰 차이가 나지 않아 이런 현상이 발생하는 듯 싶다.
lifter 는 cepstral filter 에 관여하는 변수이다.
cepstral filter 란 사람이 가지고 있는 기준 주파수와 배음 주파수가 어긋날 때 발생하는 소리 정보를 좀 더 수월하게 찾게 하기 위해 하는 알고리즘이다.
default 값은 0 이며 그 값이 0 보다 높아지면 주파수의 amplitude 가 변화한다.

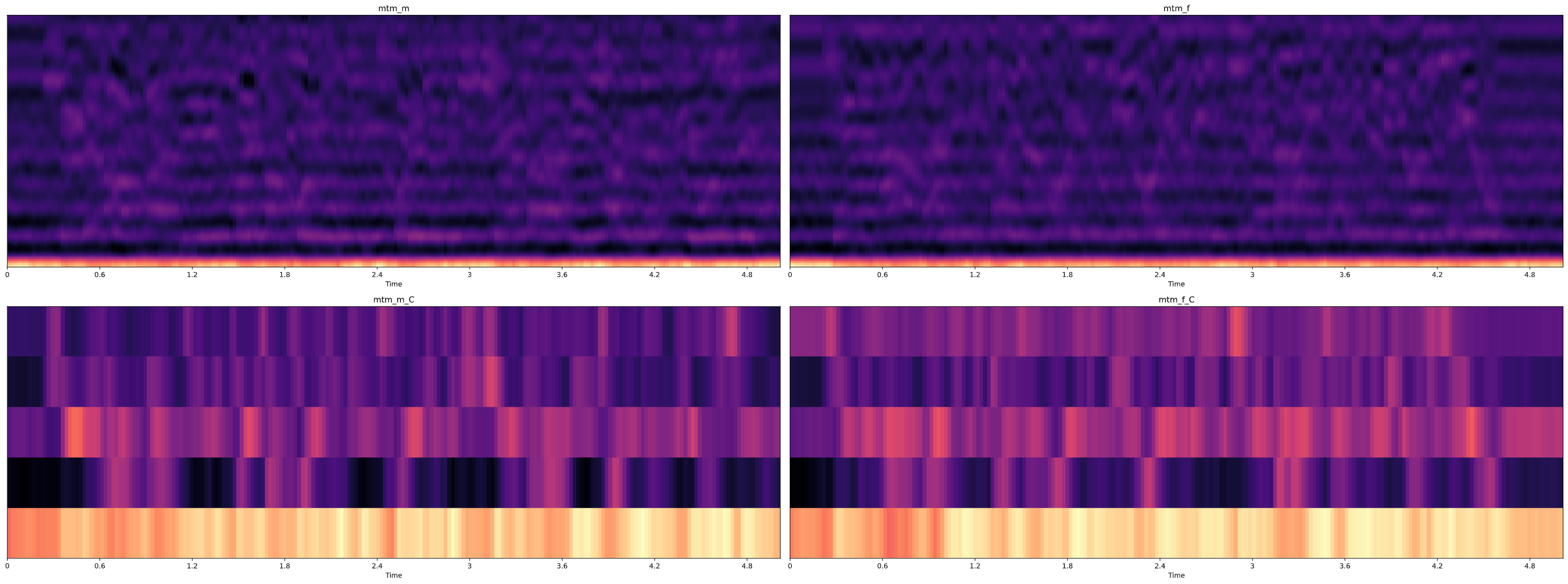
숫자가 높아질 수록 구분 되는 주파수가 뚜렷해지는데, 이는 위에서 말했던 것처럼 배음 주파수를 좀 더 명확하게 하여 기준 주파수를 쉽게 찾아낼 수 있게 하기 위함이다.
(기준 주파수는 배음 주파수 중에서 가장 낮은 값을 의미한다.)
즉 mfcc 만 주어졌을 때 mfcc_to_mel 을 이용하면 해당 오디오 파일의 기준 주파수를 알아낼 수 있다.
norm 은 normalization, 즉 정규화를 의미한다.
dct_type 에 영향을 받으며 해당 파라미터가 2, 3 일 경우엔 ortho 를, 1인 경우에는 정규화를 지원하지 않는다.
코딩을 할 때 ortho 뿐만 아니라 backward, forward 도 찾았는데 이 둘은 지원하지 않는다.
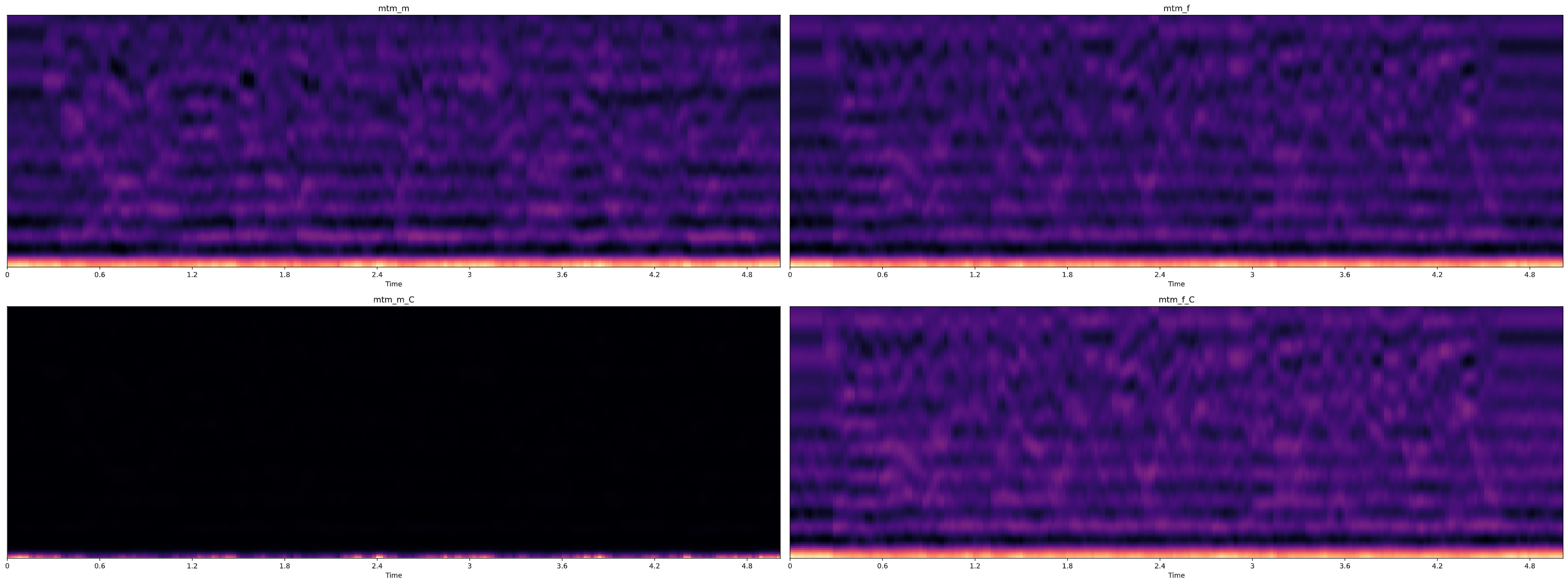
그래프에서 보면 왼쪽 아래는 완전 저주파수를 제외한 모든 주파수가 전부 사라지게 되는데 backward 과 None 값을 사용했을 때 이런 결과를 얻었다.
또한 말했다시피 forward 를 사용했을 때에도 ortho 와 차이점을 발견할 수 없었다.
ortho :
