프로젝트/화자 구분 음성 기록
librosa parameter 분석 : mfcc_to_mel_1
장비 정
2021. 4. 3. 11:39
mfcc 를 melspectrogram 화 시키는 처리이다.
# import libraries
import numpy as np
import matplotlib.pyplot as plt
import IPython.display as ipd
import librosa
import librosa.display
import soundfile as sf
import sklearn
# load data
y_m, sr_m = librosa.load(
'c:/nmb/nmb_data/주형.wav'
) # 남성 음성
y_f, sr_f = librosa.load(
'c:/nmb/nmb_data/영리.wav'
) # 여성 음성
# mfcc
# 정규화를 위해 함수 생성
def normalize(x, axis = 0):
return sklearn.preprocessing.minmax_scale(x, axis = axis)
mfcc_m = librosa.feature.mfcc(
y_m, sr = sr_m
) # mfcc 변환
mfcc_m_norm = normalize(mfcc_m, axis = 1) # MinMaxScale 을 거쳐 정규화
mfcc_f = librosa.feature.mfcc(
y_f, sr = sr_f
)
mfcc_f_norm = normalize(mfcc_f, axis = 1)
필요한 라이브러리를 임포트하고 각 남성 화자, 여성 화자의 발성 데이터를 로드한다.
그 후 mfcc 로 만들기 전 정규화를 위해 MinMaxScale 을 사용한 함수 하나를 만든다.
그 뒤 각 데이터를 mfcc 로 만들었다.
시각화를 하자면 다음과 같다.
# visualization
fig = plt.figure(figsize = (32, 12))
ax1 = fig.add_subplot(2, 2, 1)
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 2, 3)
ax4 = fig.add_subplot(2, 2, 4)
librosa.display.specshow(
mfcc_m, sr = sr_m, x_axis = 'time', ax = ax1
)
ax1.set(title = 'mfcc_m_no_norm')
librosa.display.specshow(
mfcc_f, sr = sr_f, x_axis = 'time', ax = ax2
)
ax2.set(title = 'mfcc_f_no_norm')
librosa.display.specshow(
mfcc_m_norm, sr = sr_m, x_axis = 'time', ax = ax3
)
ax3.set(title = 'mfcc_m_norm')
librosa.display.specshow(
mfcc_f_norm, sr = sr_f, x_axis = 'time', ax = ax4
)
ax4.set(title = 'mfcc_f_norm')
fig.tight_layout()
plt.show()

그래프의 윗부분은 정규화를 거치지 않은 mfcc 이며, 아래는 정규화를 거친 mfcc 이다.
왼쪽은 남성 화자의 발성, 오른쪽은 여성 화자의 발성이다.
각 파일이 mfcc 화 된 것을 확인했으면 이제 다시 mel_to_mfcc 화를 시킨다.
# mfcc_to_mel
mtm_m = librosa.feature.inverse.mfcc_to_mel(
mfcc_m_norm,
n_mels = 128,
dct_type = 2,
norm = 'ortho', # 'backward', 'ortho', 'forward' 존재
ref = 1.0,
lifter = 0
)
mtm_f = librosa.feature.inverse.mfcc_to_mel(
mfcc_f_norm,
n_mels = 128,
dct_type = 2,
norm = 'ortho',
ref = 1.0,
lifter = 0
)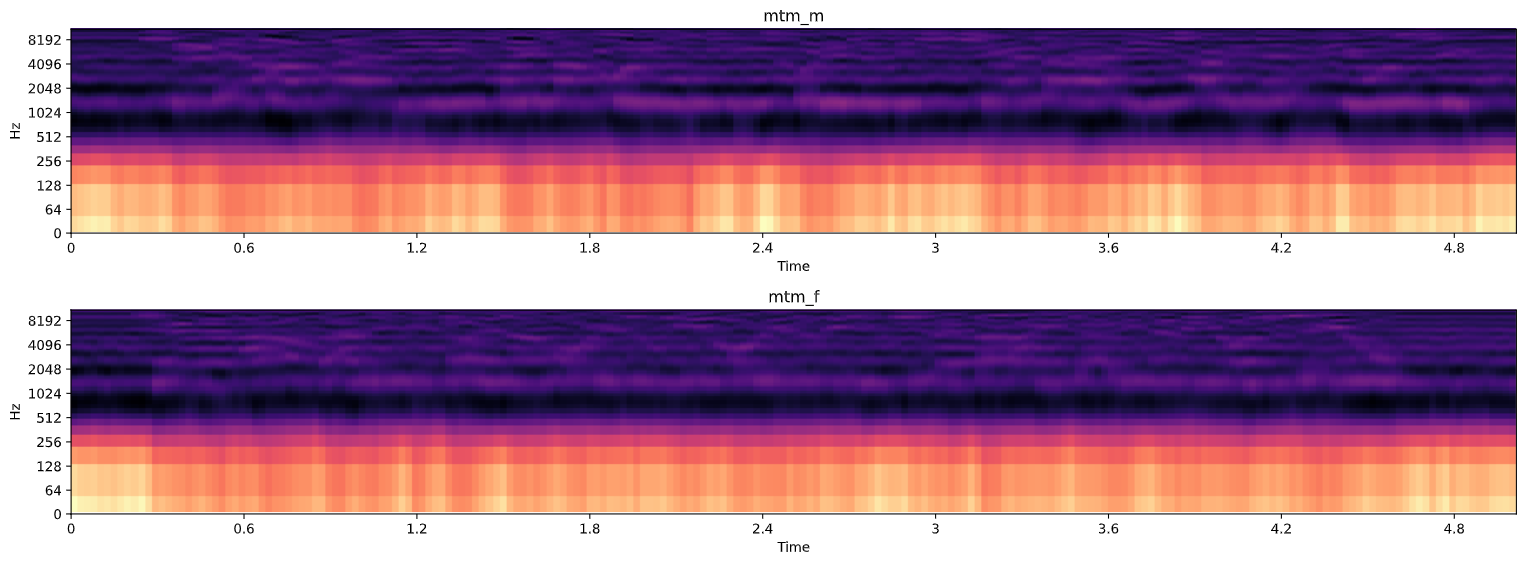
mfcc_to_mel 이 된 것을 확인했으면 기존 파일을 melspectrogram 한 것과 비교해본다.
